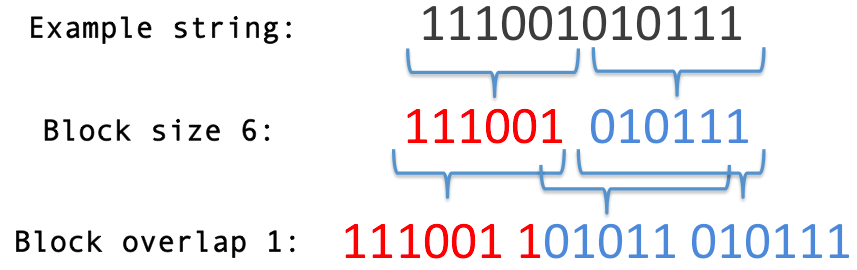
Overview
This introductory video provides a brief overview for non-experts in the area explaining how both the Coding Theorem Method ($\textit{CTM}$) and the Block Decomposition Method ($\textit{BDM}$) approximate universal measures of algorithmic complexity.
The Online Algorithmic Complexity Calculator (OACC) is a tool developed by the Algorithmic Nature Group to provide reliable estimations to non-computable functions. This is achieved through various numerical methods based upon the mathematical theory of algorithmic probability and algorithmic randomness. The estimations have a wide range of applications in a range of disciplines from molecular biology, to cognitive science, time series research (e.g. finance), and graph theory (for a list of examples, see Publications).
The OACC provides numerical approximations (upper bounds) of Algorithmic (Kolmogorov-Chaitin) Complexity (AC) for short strings ($\textit{CTM}$), for strings of any length ($\textit{BDM}_{1D}$), and for binary arrays ($\textit{BDM}_{2D}$), which can represent the adjacency matrices of unweighted graphs. These techniques are not only an alternative to the widespread use of lossless compression algorithms to approximate AC, but true approaches to AC. Lossless compression algorithms (e.g. BZIP2, GZIP, LZ) that are based upon entropy rate are not more related to AC than Shannon Entropy itself, which is unable to compress anything but statistical regularities.
Advantages of CTM and BDM over Entropy and Lossless Compression
The following plots show quantifications of the power of $\textit{CTM}$ and $\textit{BDM}$ to identify objects that look statistically random (high Entropy) but are actually causal in nature, as they are produced by short computer programs and thus recursively produced by a generation mechanism that Entropy and lossless compression algorithms based on entropy rate overlook. For example, the following strings were found to have very high Entropy (near maximal): 001010110101, 001101011010 (and binary reversion and complementaton of them) yet they were found to have low algorithmic (Kolmogorov) complexity because a small computer program (Turing machine) can generate them. This means that Shannon Entropy would have over-estimated the random nature of those strings (for every micro-state coarse-graining). Strings like these ones are the strings that produce those 'causal gaps' in the plots below.
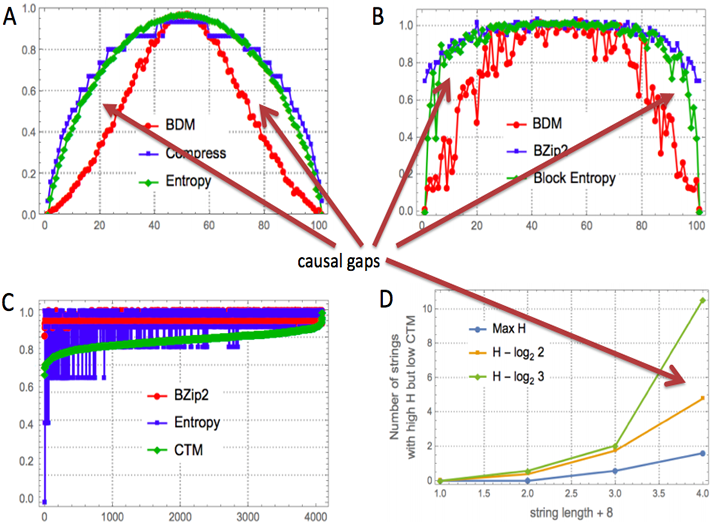
A: X axis: Plot of values for a random sample of binary strings of length 100 bits sorted by increasing number of non-zeros. Y axis: Normalized values between 0 and 1 for each of the 3 measures ($\textit{BDM}$, Compress and Entropy) used to approximate algorithmic complexity $K$. The lossless compression curve (here the algorithm used is Compress, but similar behaviour occurs with LZ, LZW, etc) closely follow the classical Bernoulli distribution for the Entropy of the set of strings. This does not come by surprise because implementations of lossless compression algorithms are actually simply Entropy-rate estimators (up to a fixed window length size). However, the $\textit{BDM}$ distribution approximates the expected theoretical semi-exponential distribution for $K$ assigning lower values to strings that are causally generated but are statistically random-looking to Entropy and compression.
B: Same test with bitstrings of length 1000 ($\textit{BDM}$ starts approximating Shannon Entropy if $\textit{CTM}$ is not updated).
C: $\textit{BDM}$ provides a much finer-grained distribution where Shannon Entropy and lossless compression algorithms retrieve only a limited number (about 5) of differentiated 'complexity' values for the all strings of length 12.
D: Number of strings (of length 12) among all $2^{12}$ bitstrings with maximum Shannon Entropy or near maximum Shannon Entropy but low algorithmic complexity estimated by $\textit{CTM}$/$\textit{BDM}$. Arrows poiting to what we call 'causal gaps' show the power gained by using $\textit{CTM}$/$\textit{BDM}$ against Shannon Entropy and compression at identifying causally generated strings and objects that may not have any statistical patterns but can be recursively/algorithmically produced with a short computer program. More information on $\textit{CTM}$ is available in this paper and on Entropy and $\textit{BDM}$ in this other one.